

Cross Validated Issue #1: Scalable Machine Learning at Netflix
How Netflix Scales Machine Learning to Power Its Media Empire



Welcome to the first ever issue of Cross Validated! This week, we are going to discuss how Netflix scales their machine learning stack.
Table of Contents
Article Spotlight: What on Earth is Retrieval-Augmented Generation (RAG)?
AI Recap: Essential News You Might Have Missed
Scalable Machine Learning at Netflix 🎥
How Netflix Scales Machine Learning to Power Its Media Empire
In case you haven’t heard of Netflix before, Netflix is a streaming service that offers a wide variety of TV shows, movies, documentaries, and other video content.
It is available in over 190 countries and has over 220 million paid subscribers worldwide. Netflix is known for its personalized recommendations, which are powered by machine learning algorithms.

Netflix uses machine learning to power many of its key features, including recommendations, artwork personalization, and promotional content creation. However, scaling machine learning to work with media assets (such as video, audio, image, etc.) presents a number of challenges, such as:
Accessing Media Assets: Media assets can be large, complex and multimodal, and accessing them in a consistent and efficient way can be difficult.
Feature Computation: Computing features from media assets can be expensive and time-consuming.
Compute Triggering and Orchestration: Once models are trained, they need to be triggered and orchestrated to run over new assets as they arrive.
Training Performance: Media model training can be computationally expensive, and scaling it to large datasets can be challenging.
Searching and Serving: Once models are trained, their outputs need to be searched for and served efficiently.
To address these challenges, Netflix has built a number of infrastructure components and leveraged open-source libraries for distributed computing:
Jasper: A library that standardizes media assets and provides a unified interface for accessing them.
Amber Feature Store: A feature store that memorizes features/embeddings tied to media entities to prevent accidental cross-computation of the same features by different analysts.
Amber Compute: A suite of infrastructure components that offers triggering capabilities to initiate the computation of algorithms with recursive dependency resolution.
Ray: A large-scale Graphical Processing Unit (GPU) training cluster based on Ray that supports multi-GPU/multi-node distributed training.
Marken: A scalable annotation service used to persist feature values. The features are versioned and strongly typed constructs associated with Netflix media entities such as videos and artwork.
Metaflow: a Python-based framework that allows the building of scalable and reliable machine learning pipelines.
These are some of the major components which enable Netflix to scale its machine learning pipelines to meet the demands of its business.
How it Works in Practice: Artwork Personalization
One example of how Netflix uses these components to scale its machine learning pipelines is in its artwork personalization system. This system uses machine learning to generate personalized artwork for each user, based on their viewing history and other factors.
The artwork personalization pipeline starts by accessing media assets through Jasper. Then, it computes features from these assets using the Amber Feature Store. Next, it triggers and orchestrates a suite of ML models to generate personalized artwork using Amber Trigger and Amber Compute.
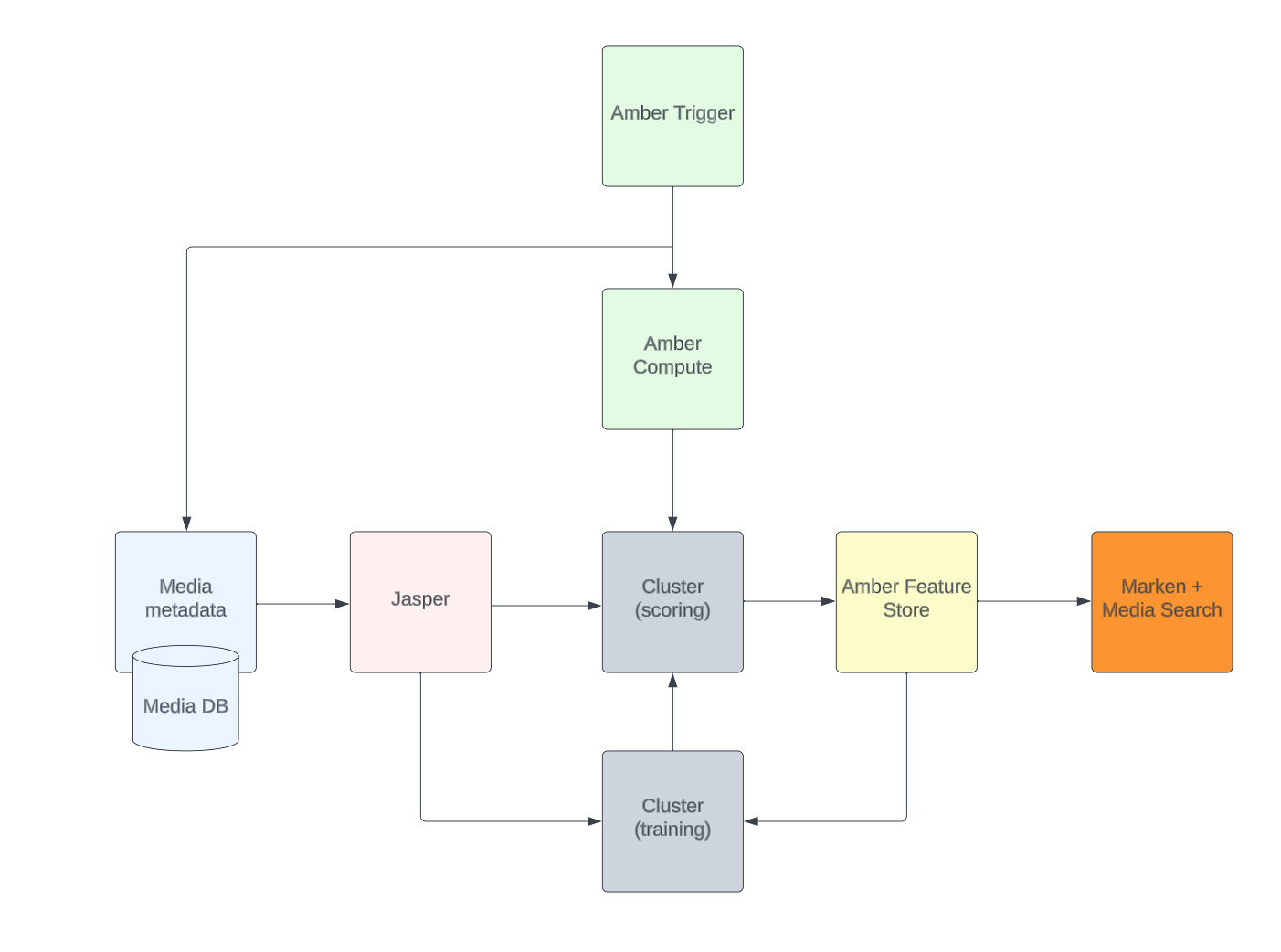
Finally, the personalized artwork is made accessible to users through Marken, which serves as a media search platform. Marken enables the efficient serving and searching of high-scoring media pairs in internal applications, thus paralleling the consumer-facing functionality that delivers customized artwork to users.
It is worth noting that the compute clusters are served using Ray.
This pipeline is able to scale to serve millions of users because of the infrastructure components that Netflix has built.
For example, the Amber Feature Store ensures that features are only computed once, which saves time and resources. The Amber Compute suite of components provides reliable and efficient triggering and orchestration of the machine learning model. And Marken provides a scalable way to search for and serve the personalized artwork.
Article Spotlight 🔦:
What on Earch is Retrieval-Augmented Generation (RAG)? (Enoch Kan)
The article introduces retrieval-augmented generation (RAG) as a technique to enhance the accuracy of large language models (LLMs) by incorporating external knowledge bases. Read more!

How did we do so far? What content would you like to see more of? Let us know by leaving a comment :)
AI Recap: Essential News You Might Have Missed 📢
OpenAI Introduces GPT Store on Dev Day:
OpenAI's Dev Day introduced significant updates and new offerings, including GPT-4 Turbo with enhanced text and image processing, the ability for users to create and publish custom GPT models, and new APIs for personal assistants and text-to-speech. The event also highlighted OpenAI's commitment to support businesses through the Copyright Shield program, reinforcing their defense against copyright infringement claims.
Read more: OpenAI Looks for Its iPhone Moment With Custom GPT Chatbot Apps (CNET)

Elon Musk Launches AI Chatbot Grok:
Elon Musk has launched Grok, an AI chatbot with advanced capabilities and access to a wealth of real-time data, through his AI startup xAI. Grok is set to compete in the generative AI market, positioning itself as a cutting-edge alternative to the current AI leaders.
Read more: Elon Musk unveils Grok, an AI chatbot with a ‘rebellious streak’ (The Guardian)
Amazon Unveils AI Model Olympus to Surpass GPT-4:
Amazon is advancing its AI capabilities with Olympus, a new large language model with 2 trillion parameters designed to exceed the performance of OpenAI's GPT-4. The model aims to enhance Amazon's suite of products and services, including its online retail platform, Alexa, and Amazon Web Services, positioning the company as a formidable player in the AI industry.
Read more: Amazon is building a LLM to rival OpenAI and Google (AI News)
First AI Safety Summit at Bletchley Park:
The AI Safety Summit 2023 was an international conference focused on the safety and regulation of artificial intelligence, marking the first ever global summit of its kind, held at Bletchley Park in the UK. The event was significant for the unveiling of the "Bletchley Declaration," a pioneering agreement among the US, the EU, China, and others, to emphasize the importance of understanding and managing AI risks collectively. This summit faced criticism regarding its lack of diversity in voice and its lack of concrete outcomes.
Read more: AI safety: How close is global regulation of artificial intelligence really? (BBC)
Chinese Influencers Embrace AI for Digital Clones:
Chinese influencers are progressively using AI to create digital clones, enabling them to generate content non-stop and meet the intense demands of the industry. This technology allows some, like the Taiwanese influencer Chen Yiru, to significantly boost their content output and income, but it raises concerns about the impact on lesser-known content creators' job security and the ethical implications of such technology.
Read more: How Chinese influencers use AI digital clones of themsleves to pump out content (The Guardian)

Beatles' 'Now and Then' Features AI-Reconstructed Lennon Vocals
The new Beatles song "Now and Then" will feature John Lennon's voice, extracted and clarified using AI technology from a demo cassette provided by Yoko Ono. Paul McCartney has indicated that this technology allowed for the mixing of the song as if it were a conventional recording, marking it as, potentially, the last Beatles record.
Read more: The Beatles release their last new song "Now and Then" — thanks to AI and archival recordings (CBS)